O Javascript está em praticamente todo site moderno. Menus animados, conteúdo carregado dinamicamente, filtros de produto, avaliações que aparecem sem recarregar a página: tudo isso passa por ele.
O problema é que o Google não lê Javascript da mesma forma que lê HTML. Há um processo adicional de renderização que consome tempo e recursos, e qualquer falha nesse caminho pode fazer com que partes inteiras do seu site nunca sejam indexadas.
E o pior: visualmente, tudo parece normal. O usuário vê a página funcionando. O Google, não necessariamente.
Neste artigo, você vai entender como o Javascript interfere no rastreamento e na indexação, quais são os problemas mais comuns e o que fazer para que o código não se torne um obstáculo para o crescimento orgânico do seu site.
O que é o JavaScript e qual a sua importância?
O JavaScript é a linguagem que dá vida à web moderna.
Ele é o responsável por transformar páginas estáticas em experiências interativas, onde botões respondem, menus se movimentam e conteúdos aparecem sem recarregar a tela.
Enquanto o HTML define a estrutura e o CSS cuida do estilo, o JavaScript adiciona comportamento.
É ele quem permite que o site converse com o usuário em tempo real.
Desde a atualização automática de preços em um e-commerce até os comentários que surgem instantaneamente em um blog, tudo isso acontece graças a ele.
Mas essa versatilidade tem um custo.
Cada vez que o JavaScript executa uma função, ele precisa ser interpretado pelo navegador, o que exige processamento e tempo.
Em um mundo em que a velocidade e a clareza são determinantes para o ranqueamento, entender como esse código afeta o SEO é essencial.
Qual a relação entre Javascript e SEO?
O Javascript, por si só, não é um vilão do SEO. Ele é uma linguagem indispensável para a web moderna e, quando bem aplicado, melhora a experiência do usuário de formas que HTML e CSS sozinhos não conseguem.
O que muda é a camada de complexidade que ele adiciona ao processo de rastreamento.
Quando o Google encontra uma página em HTML puro, o processo é direto: ele acessa o arquivo, lê o conteúdo e indexa. Com Javascript, há uma etapa a mais. O Googlebot precisa primeiro rastrear o HTML base, depois renderizar o Javascript para enxergar o que foi gerado dinamicamente, e só então indexar o resultado.
Esse intervalo entre rastrear e renderizar cria uma janela de risco. Se algo falhar nesse processo, o conteúdo que depende do Javascript pode simplesmente não entrar no índice do Google.
Pesquisas da Onely mostram que o Google leva até 9 vezes mais tempo para rastrear páginas baseadas em Javascript do que páginas em HTML estático. Isso afeta diretamente o crawl budget, que é o limite de páginas que o Googlebot está disposto a processar em um determinado período.
Para sites menores, esse impacto pode parecer invisível no início. Para sites com muitas páginas, é uma limitação real que compromete a cobertura de indexação.
Além disso, o Javascript afeta diretamente a performance. Scripts pesados, bibliotecas redundantes e chamadas a APIs externas aumentam o tempo de carregamento e comprometem os Core Web Vitals, que são métricas que o Google usa como critério de ranqueamento.
Outro ponto que poucos consideram: redes sociais como Facebook, Twitter e LinkedIn não renderizam Javascript. Se os metadados Open Graph e Twitter Cards do seu site são gerados via script, os links compartilhados nessas plataformas aparecem sem imagem e sem descrição, o que reduz o clique mesmo fora do Google.
Se o seu site já apresenta quedas de tráfego ou páginas que somem do índice sem explicação aparente, o Javascript pode estar no centro do problema. Entender o que faz um site cair no Google é o primeiro passo para identificar se a causa é técnica ou de outra natureza.
E para quem está construindo presença orgânica do zero, entender como colocar um site no Google com uma base técnica sólida evita que esses problemas apareçam mais tarde, quando são mais difíceis de corrigir.
Como o Google renderiza um site com conteúdo dinâmico em JavaScript?
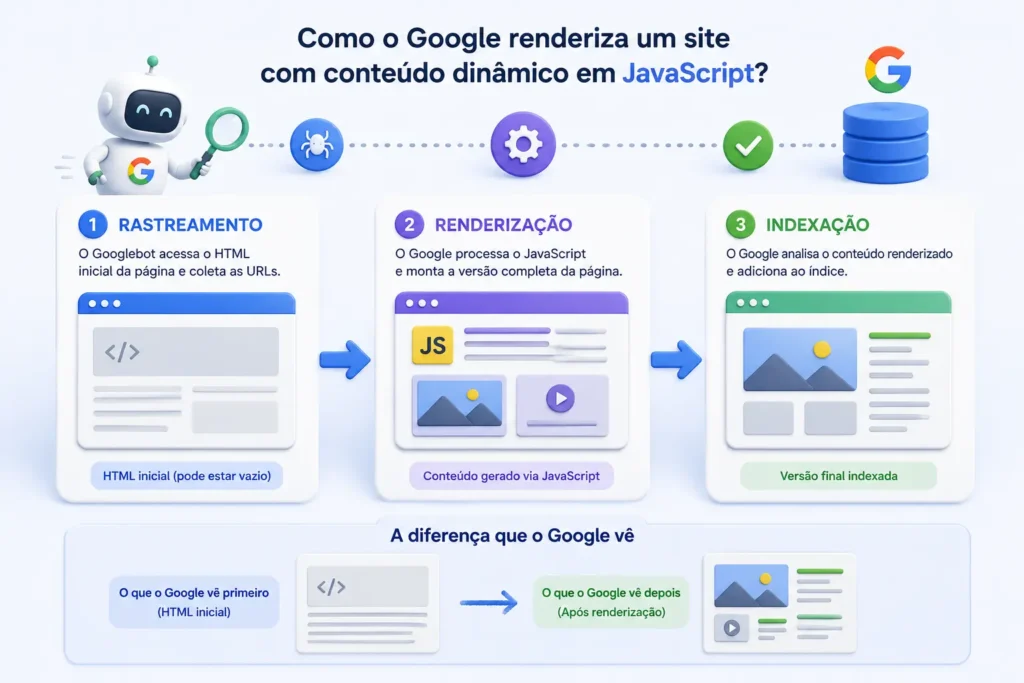
Para entender por que o Javascript cria desafios de SEO, é preciso visualizar como o Google processa uma página do início ao fim. O caminho tem três etapas: rastreamento, renderização e indexação. Cada uma delas pode ser afetada pelo uso de Javascript.
Rastreamento é o primeiro contato do Googlebot com o seu site. Ele acessa o HTML base da página e coleta as URLs encontradas. Em um site tradicional, grande parte do conteúdo já está visível nesse HTML. Em sites que dependem de Javascript, esse HTML inicial pode estar quase vazio, com o conteúdo real aparecendo apenas depois que os scripts são executados.
Renderização é a etapa em que o Google processa o Javascript para montar a versão completa da página, da forma que um usuário a veria no navegador. Esse processo é feito pelo Google Web Rendering Service (WRS) e consome recursos significativos. Por isso, o Google mantém uma fila de páginas aguardando renderização, o que pode atrasar a indexação por dias ou até semanas.
Indexação acontece depois que o conteúdo foi renderizado. O Google avalia o que conseguiu ler e decide o que entra no seu índice. Se a renderização falhou, se houve timeout ou se scripts externos não carregaram a tempo, parte do conteúdo pode se perder nessa etapa.
Há um detalhe importante sobre como o Googlebot se comporta durante esse processo: ele não age como um navegador comum.
Cookies e dados de sessão são apagados entre carregamentos, ele não clica em botões, não rola a página e pode optar por não carregar recursos que considera desnecessários para a renderização. Se o seu conteúdo depende de alguma dessas interações para aparecer, o Google provavelmente não vai vê-lo.
Outro ponto relevante: o Google usa a versão mais recente do Chrome para renderizar páginas, mas com limitações específicas do Googlebot. Isso significa que recursos que funcionam perfeitamente no navegador do usuário podem não ser processados da mesma forma pelo robô.
Quais os problemas causados por Javascript no SEO?
O Javascript, quando mal implementado, cria obstáculos que o Google não avisa diretamente. O site funciona normalmente para quem visita, mas o rastreador enfrenta uma série de barreiras que comprometem a indexação e o ranqueamento.
Abaixo estão os principais problemas que surgem na prática.
Problemas de linkagem interna
Quando menus, botões de navegação ou links entre páginas são gerados exclusivamente por Javascript, o Googlebot pode não conseguir segui-los. O resultado é que páginas existentes no site ficam inacessíveis para o rastreador, como se não tivessem nenhum caminho levando até elas.
Esse é um dos problemas mais silenciosos do Javascript SEO. A página existe, está publicada, mas o Google nunca a encontra porque nenhum link em HTML aponta para ela.
Uma arquitetura de links internos bem estruturada depende de âncoras em HTML estático. Quando a linkagem depende de Javascript para existir, a distribuição de autoridade entre as páginas fica comprometida e o rastreamento se torna imprevisível.
Acessibilidade de conteúdo para rastreadores
O Google ainda depende do HTML para compreender o conteúdo de uma página. Quando textos, descrições, títulos ou blocos de informação só aparecem após a execução de scripts, o rastreador precisa aguardar a renderização para ter acesso a eles.
Se houver qualquer falha nesse processo, como um erro de script, um timeout ou um recurso externo que não carregou, esse conteúdo simplesmente não é indexado.
Isso é especialmente comum em e-commerces que carregam descrições de produto, avaliações e preços de forma dinâmica. Do ponto de vista do usuário, tudo aparece. Do ponto de vista do Googlebot, pode haver apenas um HTML base quase vazio.
Acessibilidade de conteúdo para usuários
O Javascript também pode criar barreiras para pessoas que usam tecnologias assistivas, como leitores de tela. Elementos controlados por scripts nem sempre são interpretados corretamente por essas ferramentas, o que compromete a experiência de usuários com deficiência visual.
Além disso, sites com dependência intensa de Javascript tendem a travar em conexões lentas ou em dispositivos com menos capacidade de processamento. O conteúdo demora para aparecer, a página parece quebrada por alguns segundos e o visitante abandona antes mesmo de ver o que estava procurando.
Esse comportamento afeta diretamente métricas de engajamento que o Google observa. Uma taxa de rejeição alta em páginas que demoram para renderizar é um sinal de que a experiência está abaixo do esperado, e isso tem peso no ranqueamento.
O impacto é ainda maior no mobile. Com recursos de processamento mais limitados, dispositivos móveis demoram mais para executar scripts pesados. Considerando que o Google usa a versão mobile do site como base para indexação no modelo mobile-first, qualquer problema de Javascript que afete o carregamento em dispositivos menores é um problema de SEO direto.
Problemas de renderização e tempo de resposta
Cada script que o navegador ou o Googlebot precisa executar consome tempo e processamento. Quanto mais Javascript uma página carrega, mais lenta tende a ser a renderização. Mas o problema vai além da velocidade: em muitos casos, o conteúdo simplesmente não aparece.
Quando o Google tenta renderizar uma página e encontra scripts que demoram demais para executar, ele pode atingir o limite de tempo disponível para aquela renderização e seguir para a próxima URL. O que ficou para trás não é indexado. Não há aviso, não há erro visível no Search Console. O conteúdo some silenciosamente do índice.
Isso acontece com mais frequência do que parece. Blocos de texto, títulos, descrições de produto e até o conteúdo principal de uma página podem depender de um script para aparecer. Se esse script falhar, demorar ou não for carregado a tempo, o Google enxerga uma página vazia ou incompleta.
Scripts de terceiros agravam o problema. Pixels de rastreamento, widgets de chat, ferramentas de analytics mal configuradas e integrações com plataformas externas adicionam camadas de processamento que o Googlebot pode simplesmente ignorar ou não conseguir concluir dentro do tempo disponível.
Esse impacto também aparece nas métricas de Core Web Vitals. O LCP (Largest Contentful Paint) é diretamente afetado quando o maior elemento visível da página depende de um script para ser renderizado. O INP (Interaction to Next Paint) sofre quando há Javascript pesado bloqueando a resposta da página. E um TTFB (Time to First Byte) alto indica que o servidor está processando demais antes de entregar qualquer conteúdo ao rastreador.
No mobile, o cenário é ainda mais crítico. Dispositivos com menor capacidade de processamento demoram mais para executar scripts, e o Google usa exatamente a versão mobile para indexar o site no modelo mobile-first. Um problema de renderização que parece aceitável no desktop pode ser devastador para a indexação mobile.
Falhas em aplicações de página única (SPAs)
As SPAs são aplicações construídas para carregar tudo dentro de uma única página, sem recarregamentos entre navegações. Frameworks como React, Vue.js e Angular são a base da maioria delas.
O desafio para o SEO é estrutural. O HTML inicial entregue pelo servidor costuma estar praticamente vazio. Todo o conteúdo, incluindo textos, links e metadados, é injetado pelo Javascript depois que o script é executado no navegador.
Para o usuário, a experiência é fluida. Para o Googlebot, é um problema sério. Se a renderização atrasar ou falhar, o rastreador encontra apenas um HTML básico sem conteúdo relevante para indexar. Páginas inteiras da aplicação podem ficar invisíveis para o Google, mesmo estando acessíveis para qualquer visitante humano.
Outro ponto crítico nas SPAs é a navegação interna. Como as transições entre seções não geram um recarregamento real de página, o Googlebot pode não perceber que está diante de conteúdos distintos. URLs que mudam via Javascript sem um tratamento correto de histórico de navegação podem ser interpretadas como uma única página, o que compromete a indexação individual de cada seção.
SPAs também tendem a ter problemas com metadados dinâmicos. Títulos e descrições que mudam conforme a página acessada, quando gerados por Javascript, podem não ser capturados corretamente pelo Google, que lê os metadados do HTML inicial e nem sempre aguarda a atualização feita pelo script.
Conteúdo ausente ou atrasado na renderização
Nem sempre o problema é uma falha completa. Em muitos casos, o conteúdo existe, o script funciona, mas o timing está errado.
O Google não espera indefinidamente pela renderização de uma página. Há um limite de tempo e recursos disponíveis para cada URL processada. Quando o conteúdo depende de chamadas a APIs externas, carregamento assíncrono de dados ou scripts que executam depois de outros scripts, há risco real de o Googlebot capturar uma versão incompleta da página.
Esse conteúdo atrasado pode ser exatamente o que mais importa para o ranqueamento: o texto principal do artigo, a descrição do produto, as avaliações de clientes, os links de navegação. Tudo isso pode estar presente na versão que o usuário vê e ausente na versão que o Google indexa.
A pesquisa da Onely mostrou que, em média, conteúdo gerado por Javascript não foi indexado em 25% dos casos testados em sites de grande porte como Nike, H&M e Sephora. Um em cada quatro conteúdos simplesmente não entrou no índice, mesmo estando visível para qualquer visitante.
O diagnóstico mais direto para esse problema é comparar o HTML de resposta com o HTML renderizado no Google Search Console, usando a ferramenta de inspeção de URL. Se o conteúdo aparece apenas na versão renderizada, o Google está dependendo de um segundo processamento para enxergá-lo, e esse processamento nem sempre acontece dentro do prazo esperado.
Diferença entre HTML de resposta e HTML renderizado
Esse é um dos problemas mais comuns e menos percebidos no Javascript SEO.
O HTML de resposta é o código que o servidor entrega ao Googlebot no momento do rastreamento. É o ponto de partida, o que chega primeiro. O HTML renderizado é a versão final da página depois que o Javascript executou e preencheu o conteúdo dinamicamente.
Em sites bem estruturados, as duas versões são muito parecidas. O HTML de resposta já contém o essencial: título, texto principal, metadados, links de navegação. O Javascript complementa com interatividade, mas não é o responsável por entregar o conteúdo central.
Em sites com dependência intensa de Javascript, a diferença entre as duas versões pode ser enorme. O HTML de resposta chega vazio ou quase vazio, e todo o conteúdo visível para o usuário só existe depois da renderização.
Essa diferença tem um custo direto. O Google precisa gastar recursos adicionais para processar a versão renderizada, e há sempre o risco de esse processamento não acontecer completamente. Quanto maior a lacuna entre o HTML de resposta e o HTML renderizado, maior a instabilidade da indexação.
Testar isso é simples: basta acessar a ferramenta de inspeção de URL no Google Search Console, clicar em “Ver página testada” e comparar as duas versões. Se o conteúdo principal só aparece na versão renderizada, a estrutura técnica precisa de atenção.
Metadados e canônicas modificadas por JavaScript
Os metadados de uma página, como título, meta description e canonical tag, são informações que o Google lê com prioridade. Eles orientam o rastreador sobre o que a página é, qual URL deve ser considerada a principal e como o conteúdo deve ser apresentado nos resultados de busca.
O problema aparece quando esses elementos são definidos ou modificados via Javascript. O Google lê o HTML de resposta primeiro, antes de renderizar qualquer script. Se o título que está no HTML inicial for diferente do título que o Javascript injeta depois, o rastreador pode capturar a versão errada, ou alternar entre as duas de forma imprevisível.
Com as canonical tags, o risco é ainda maior. Uma canonical tag definida no HTML inicial aponta para uma URL. O Javascript, depois da renderização, sobrescreve essa tag e aponta para outra. O Google pode interpretar qualquer uma das duas como a URL canônica, o que gera inconsistência de indexação e pode fazer com que a página errada seja considerada a versão principal.
Esse problema é especialmente comum em SPAs e em sites que usam frameworks modernos para gerenciar metadados dinamicamente. A solução mais segura é garantir que título, meta description, canonical tag e qualquer outra tag de metadado estejam presentes e corretos no HTML de resposta, antes mesmo de qualquer script ser executado.
Metadados gerados exclusivamente por Javascript também afetam o compartilhamento em redes sociais. Facebook, Twitter e LinkedIn não renderizam Javascript ao rastrear URLs compartilhadas. Se as tags Open Graph e Twitter Cards dependem de script para existir, os links compartilhados aparecem sem imagem, sem título e sem descrição, o que reduz drasticamente o engajamento mesmo fora do Google.
Bloqueio de recursos e erros no rastreamento
O arquivo robots.txt é uma das primeiras coisas que o Googlebot consulta ao visitar um site. Ele define o que pode e o que não pode ser rastreado. Quando arquivos Javascript essenciais para a renderização estão bloqueados nesse arquivo, o Google tenta processar a página sem os scripts necessários e o resultado é uma versão incompleta ou completamente quebrada.
Esse é um erro que parece improvável, mas acontece com frequência em sites que passaram por migrações, atualizações de plataforma ou configurações feitas sem revisão técnica. O bloqueio pode ter sido intencional em algum momento e simplesmente nunca foi removido. O efeito é silencioso: o site continua funcionando normalmente para o usuário, mas o Google enxerga uma versão diferente da página.
Além do robots.txt, outros fatores técnicos podem bloquear o rastreamento de recursos Javascript:
- Restrições de CORS que impedem o Googlebot de acessar scripts hospedados em domínios externos.
- Autenticação exigida para carregar determinados recursos, que o Googlebot não consegue fornecer.
- Erros de carregamento de scripts causados por dependências quebradas, versões desatualizadas ou conflitos entre plugins.
- Redirecionamentos Javascript que levam o Googlebot para URLs diferentes das que o usuário vê, criando inconsistências de rastreamento.
Redirecionamentos feitos via Javascript merecem atenção especial. Enquanto um redirecionamento 301 no servidor é imediato e claro para o Google, um redirecionamento feito por script depende da renderização para ser executado. Isso significa que o Googlebot pode rastrear a URL de origem, nunca processar o redirecionamento e indexar uma página que deveria estar apontando para outra.
Revisar periodicamente o robots.txt, o sitemap.xml e os relatórios de cobertura no Google Search Console é a forma mais direta de identificar se algum recurso essencial está sendo bloqueado sem intenção.
Entendendo a renderização e seus subtipos
Antes de partir para as soluções, é preciso entender as diferentes formas de entregar conteúdo ao navegador e ao Googlebot. A escolha do tipo de renderização é uma decisão técnica que tem impacto direto em como o Google vai enxergar o seu site.
Há três abordagens principais: renderização do lado do cliente (CSR), renderização do lado do servidor (SSR) e renderização dinâmica. Cada uma tem características, vantagens e limitações específicas para o SEO.
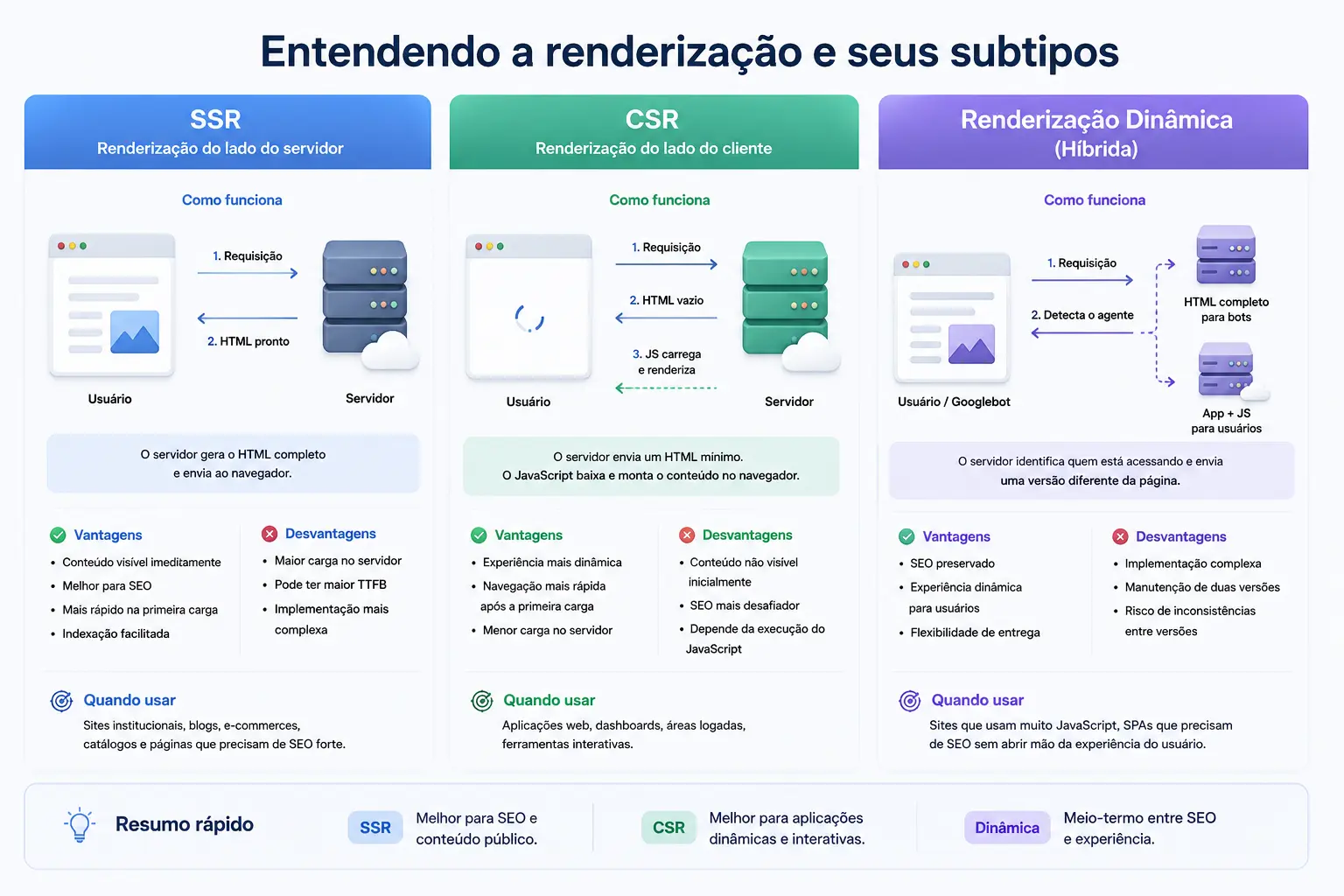
Renderização do lado do cliente (CSR)
Na renderização do lado do cliente, o servidor entrega ao navegador um HTML praticamente vazio. É o Javascript, executado no navegador do usuário ou no Googlebot, que preenche o conteúdo dinamicamente depois do carregamento inicial.
Frameworks como React, Vue.js e Angular trabalham por padrão com CSR. A experiência para o usuário pode ser fluida e responsiva, mas o custo para o SEO é significativo.
O Googlebot recebe um HTML inicial sem conteúdo relevante e precisa aguardar a execução completa dos scripts para enxergar o que a página realmente contém. Se qualquer etapa desse processo falhar, se houver timeout, erro de script ou recurso externo que não carregue, o Google indexa uma página vazia.
Além disso, o CSR aumenta o tempo de processamento necessário para cada página. Em sites com muitas URLs, isso pressiona o crawl budget e pode fazer com que páginas importantes sejam rastreadas com menos frequência ou simplesmente ignoradas.
Para sites que dependem de CSR e não podem migrar para outra abordagem no curto prazo, a saída mais comum é combinar o CSR com técnicas de pré-renderização ou migrar gradualmente para SSR nas páginas mais estratégicas.
Renderização do lado do servidor (SSR)
Na renderização do lado do servidor, o Javascript é executado antes de o conteúdo ser enviado ao navegador. O servidor processa os scripts, monta a página completa e entrega um HTML já renderizado tanto para o usuário quanto para o Googlebot.
O resultado é direto: o rastreador recebe o conteúdo na primeira solicitação, sem depender de um segundo processamento. Títulos, textos, links internos e metadados já estão presentes no HTML de resposta, exatamente como deveria ser.
Do ponto de vista de SEO, o SSR é a abordagem mais segura. Ele reduz o TTFB, melhora o LCP, facilita a indexação e elimina a dependência da fila de renderização do Google. Frameworks modernos como Next.js, Nuxt.js e SvelteKit já oferecem suporte nativo ao SSR, o que torna a implementação mais acessível do que era alguns anos atrás.
Vale deixar claro que o SSR também tem limitações. A carga no servidor aumenta, já que cada requisição exige processamento antes da resposta. Em sites com alto volume de acessos, isso precisa ser gerenciado com estratégias de cache bem configuradas para não comprometer a performance.
Mas para a maioria dos projetos que sofrem com problemas de indexação causados por Javascript, migrar para SSR nas páginas mais críticas, como home, categorias e páginas de produto, já resolve boa parte dos obstáculos de rastreamento.
Renderização dinâmica
A renderização dinâmica funciona como um intermediário entre o CSR e o SSR. A lógica é simples: quando a requisição vem de um rastreador, o servidor entrega uma versão pré-renderizada da página em HTML estático. Quando vem de um usuário comum, o site carrega normalmente com Javascript.
Ferramentas como Prerender.io e Rendertron automatizam esse processo, identificando o user agent da requisição e servindo a versão adequada para cada visitante.
Para SPAs ou sites com dependência intensa de Javascript que não podem ser reescritos do zero, a renderização dinâmica é uma saída prática. Ela garante que o Google receba o conteúdo completo sem exigir uma refatoração profunda da arquitetura do site.
O ponto de atenção mais importante nessa abordagem é a paridade de conteúdo. A versão entregue ao Googlebot precisa ser idêntica à versão que o usuário vê. Qualquer diferença relevante entre as duas, seja em texto, links ou metadados, pode ser interpretada pelo Google como cloaking, uma prática que viola as diretrizes da plataforma e pode resultar em penalizações.
O próprio Google reconhece a renderização dinâmica como uma solução válida, mas deixa claro que ela deve ser tratada como uma medida temporária. A recomendação oficial é migrar para SSR assim que possível, já que a renderização dinâmica adiciona uma camada de complexidade à infraestrutura e exige manutenção contínua para garantir que as versões se mantenham sincronizadas.
E como resolver os problemas causados por Javascript no SEO?
Identificar que o Javascript está causando problemas é metade do caminho. A outra metade é saber por onde começar a resolver sem criar novos problemas no processo.
As soluções não passam por eliminar o Javascript do site. Passam por garantir que o conteúdo essencial chegue ao Google de forma clara, completa e sem depender de um processamento adicional que pode falhar.
Entenda como o conteúdo é entregue
O primeiro passo é entender exatamente o que o Google recebe quando acessa o seu site. Não o que você vê no navegador, mas o que chega ao rastreador antes de qualquer renderização.
A ferramenta mais direta para isso é a inspeção de URL no Google Search Console. Ao acessar uma página pelo painel e clicar em “Ver página testada”, você tem acesso ao HTML de resposta e ao HTML renderizado lado a lado. A comparação entre os dois revela o que o Google precisa processar para enxergar o conteúdo completo.
Se o conteúdo principal, os títulos, os links internos ou os metadados só aparecem na versão renderizada, o site tem uma dependência de Javascript que precisa ser endereçada.
Outro teste útil é desativar o Javascript diretamente no navegador, usando extensões como Quick Javascript Switcher no Chrome. O que a página exibe com o Javascript desligado é, em grande parte, o que o Google vê na primeira passagem. Se blocos inteiros de conteúdo desaparecem, esses elementos estão em risco de não serem indexados.
Ferramentas de auditoria como Screaming Frog e Sitebulb também permitem comparar o que o Googlebot rastreia antes e depois da renderização, o que ajuda a identificar falhas específicas de forma mais sistemática em sites com muitas páginas.
Esse diagnóstico precisa acontecer antes de qualquer intervenção técnica. Sem entender como o conteúdo está sendo entregue, qualquer mudança pode resolver um problema e criar outro.
Aplique a renderização do lado do servidor
Se o diagnóstico confirmou que o conteúdo essencial do site depende de Javascript para aparecer, a migração para SSR é a mudança com maior impacto direto na indexação.
Com o SSR, o servidor processa os scripts antes de entregar a resposta ao Googlebot. O HTML que chega ao rastreador já contém o conteúdo completo: textos, títulos, links internos, metadados e dados estruturados. Não há fila de renderização, não há risco de timeout e não há dependência de um segundo processamento.
Na prática, a migração para SSR costuma começar pelas páginas mais estratégicas do site, aquelas que concentram o maior volume de tráfego orgânico ou que têm maior potencial de ranqueamento. Home, categorias principais e páginas de produto são os pontos de partida mais comuns.
Frameworks como Next.js para React e Nuxt.js para Vue.js oferecem suporte nativo ao SSR com uma estrutura de configuração acessível para equipes de desenvolvimento com experiência nesses ecossistemas. O SvelteKit segue a mesma linha para quem trabalha com Svelte.
Um detalhe que precisa de atenção durante a implementação: o SSR aumenta a carga no servidor, já que cada requisição exige processamento antes da resposta. Para absorver esse impacto sem comprometer a performance, é preciso combinar o SSR com uma estratégia de cache bem configurada, seja no próprio servidor, em uma CDN ou em ambos.
Feito corretamente, o SSR elimina a maioria dos problemas de indexação causados por Javascript e melhora simultaneamente as métricas de Core Web Vitals, especialmente o LCP e o TTFB, que são diretamente afetados pela velocidade de entrega do conteúdo pelo servidor.
Sirva conteúdo em HTML estático
Para além do SSR, há situações em que a melhor decisão técnica é simplesmente servir o conteúdo em HTML estático desde o início, sem depender de nenhum tipo de renderização dinâmica.
Essa abordagem faz mais sentido para conteúdos que não mudam com frequência: páginas institucionais, artigos de blog, landing pages e páginas de categoria com estrutura estável. Para esses casos, gerar o HTML no momento do build e servir arquivos estáticos é a forma mais eficiente de garantir que o Google receba exatamente o que precisa, sem nenhuma camada adicional de processamento.
A diferença no rastreamento é imediata. O Googlebot acessa o arquivo, lê o conteúdo e segue em frente. Sem renderização, sem fila, sem risco de timeout. O tempo de indexação tende a ser mais curto e a cobertura de páginas mais consistente.
Do ponto de vista de performance, HTML estático também entrega os melhores resultados em métricas de velocidade. O TTFB cai drasticamente porque o servidor não precisa processar nada antes de responder. O LCP melhora porque o conteúdo principal já está no HTML que o navegador recebe.
Frameworks como Gatsby, Astro e Eleventy são construídos especificamente para geração de sites estáticos, com suporte a integrações modernas e flexibilidade suficiente para a maioria dos projetos de conteúdo. O Next.js também oferece geração estática por página, o que permite combinar SSR e HTML estático dentro de um mesmo projeto conforme a necessidade de cada tipo de página.
Entender como estruturar o site com uma base em HTML sólida, antes mesmo de pensar em Javascript, é um dos fundamentos do SEO técnico que mais impacta a indexação no longo prazo. Aqui você encontra uma visão mais aprofundada sobre como a estrutura em HTML afeta diretamente o rastreamento do site.
A tag <noscript> é um recurso nativo do HTML que define o que deve ser exibido quando o Javascript está desativado ou não pode ser executado. Para o SEO, ela funciona como uma camada de segurança: garante que o conteúdo essencial esteja acessível ao Googlebot mesmo quando a renderização dos scripts falha.
A lógica é direta. Tudo que está dentro de um bloco <noscript> é entregue em HTML puro ao rastreador que não processa Javascript. Isso inclui textos, links, imagens e qualquer outro elemento que normalmente dependeria de um script para aparecer.
Na prática, os casos de uso mais relevantes são:
- Links de navegação gerados por Javascript que precisam estar acessíveis ao Googlebot para garantir o rastreamento das páginas internas.
- Conteúdo principal de páginas que dependem de carregamento assíncrono, como descrições de produto ou textos de categoria.
- Metadados de imagens, especialmente em galerias ou sliders controlados por script.
- Dados estruturados que precisam estar presentes no HTML inicial para serem lidos corretamente.
Um ponto que merece atenção: o conteúdo dentro do <noscript> precisa ser idêntico ao que o usuário vê com Javascript ativo. Inserir conteúdo diferente, seja mais extenso ou diferente em mensagem, pode ser interpretado como cloaking pelo Google, com as mesmas consequências de qualquer outra prática que serve conteúdo diferente para rastreadores e usuários.
O <noscript> não substitui uma arquitetura bem construída em SSR ou HTML estático. Ele é um complemento, uma rede de segurança para situações onde o Javascript pode falhar e o conteúdo não pode correr o risco de desaparecer do índice.
Desconfia que o seu site tem problemas com Javascript? Contate um especialista!
Problemas de Javascript no SEO raramente aparecem de forma óbvia. O site funciona, as páginas carregam, o usuário não percebe nada. Mas o Google enxerga uma versão diferente, com conteúdo incompleto, links inacessíveis e metadados inconsistentes.
Seu site tem problemas técnicos de SEO?
Responda estas 10 perguntas para descobrir a gravidade dos problemas técnicos do seu site

Esse tipo de problema exige um diagnóstico técnico cuidadoso. Não basta rodar uma ferramenta automática e interpretar o relatório gerado. É preciso entender como o conteúdo está sendo entregue, onde a renderização está falhando e qual é o impacto real na cobertura de indexação.
Se o tráfego orgânico está estagnado sem explicação aparente, se páginas publicadas não aparecem no Google mesmo depois de semanas, ou se o Search Console mostra erros de cobertura que não fazem sentido à primeira vista, o Javascript pode estar no centro do problema.
Trabalho com diagnóstico e correção de problemas técnicos de SEO em sites que dependem de Javascript, com foco em identificar exatamente onde o rastreamento está sendo comprometido e o que precisa mudar na estrutura para que o Google consiga indexar o conteúdo com consistência.
O ponto de partida é sempre uma auditoria de SEO técnico que mapeia os problemas reais do site, sem relatório genérico. Para quem precisa de acompanhamento contínuo após o diagnóstico inicial, o acompanhamento técnico de SEO garante que os ajustes sejam monitorados e que novos problemas sejam identificados antes de impactar o orgânico.
Entre em contato agora e descubra o que o Javascript está escondendo do Google no seu site.
Conclusão
O Javascript não é um problema em si. É uma linguagem essencial para a web moderna e vai continuar sendo. O problema está em como ele é implementado e no que acontece quando o Google tenta processar o que foi construído com ele.
Renderização que falha, conteúdo que só aparece depois de um script executar, links internos invisíveis para o rastreador, metadados que mudam depois do carregamento inicial. Cada um desses pontos, isolado, já é capaz de comprometer a indexação de páginas inteiras. Combinados, criam um cenário onde o site parece funcionar perfeitamente para o usuário enquanto o Google enxerga uma versão incompleta e inconsistente.
A boa notícia é que esses problemas têm solução. SSR nas páginas estratégicas, HTML estático onde faz sentido, <noscript> como camada de segurança, canonical tags e metadados presentes no HTML de resposta desde o início. São decisões técnicas que, tomadas na ordem certa, eliminam a maioria dos obstáculos que o Javascript cria para o rastreamento.
O que não tem solução fácil é ignorar o problema. Sites que dependem de Javascript sem nenhum cuidado técnico acumulam débito de indexação ao longo do tempo, e esse débito aparece na forma de páginas que somem do índice, tráfego orgânico que não evolui e ranqueamentos que caem sem uma causa óbvia.
SEO técnico é, em grande parte, garantir que o Google consiga ler o que você construiu. O Javascript, quando bem estruturado, não impede isso. Quando mal implementado, cria barreiras que nenhuma estratégia de conteúdo resolve sozinha.
Especialista em SEO Técnico. Identifico e corrijo o que impede o Google de rastrear, indexar e ranquear sites. Atendo WordPress, Shopify, Tray, Nuvemshop e sites customizados.